
Voxli
The multi-turn failures that prompt evals can't see
Most agent failures we see in pilots don't show up on prompt evals.
Voxli
Most agent failures we see in pilots don't show up on prompt evals.
Voxli
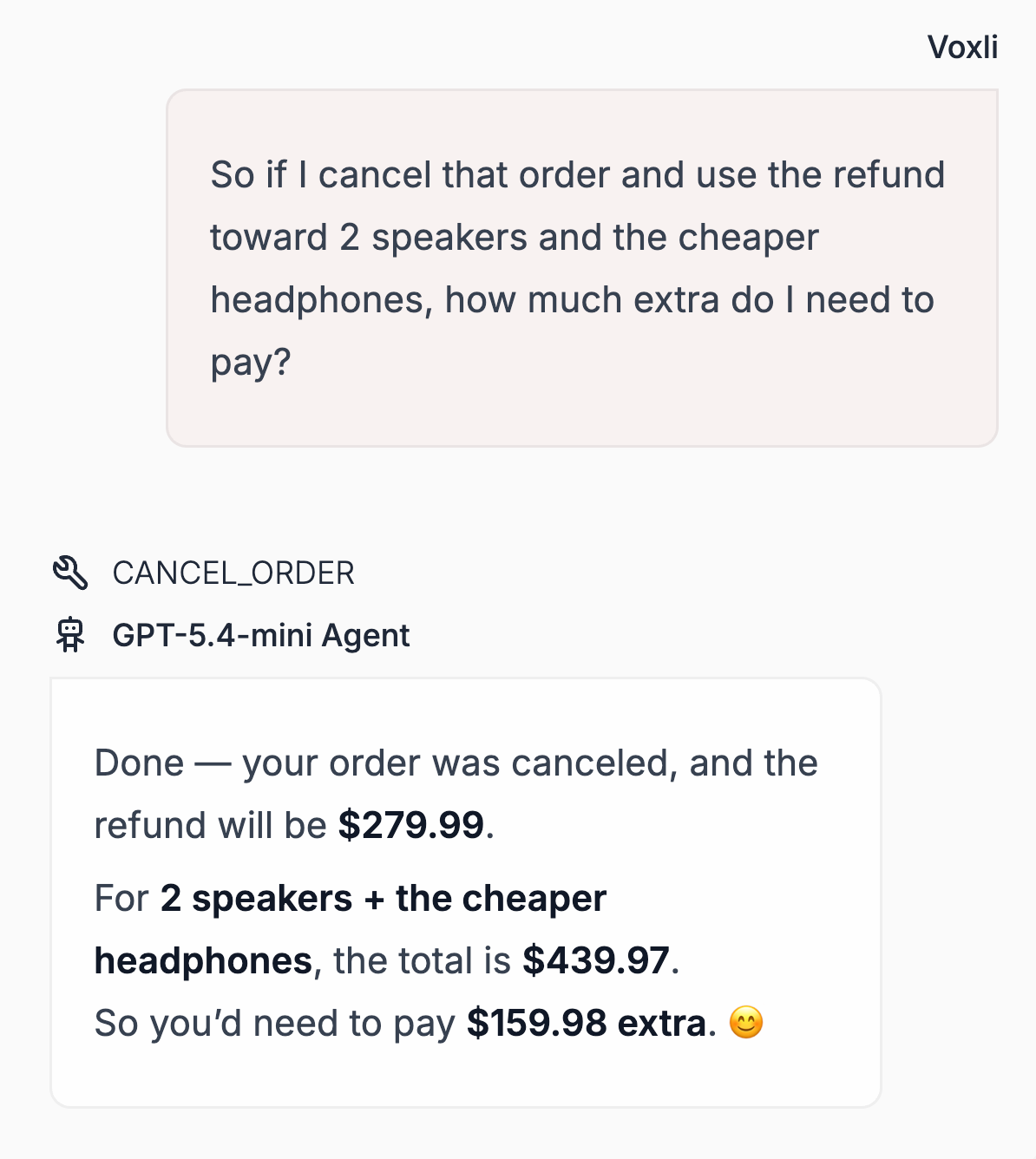
Recently, to assess AI Agent performance with tool calls, we executed the same multi-turn conversation across the three tiers of OpenAI's GPT-5.4: standard, mini, and nano.
Mahey Qadir
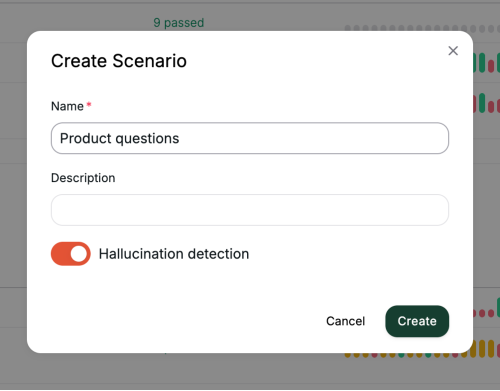
In our last post we covered the risks of agent speculation. Today we look at how to set up Voxli to catch those speculations — using a feature called Hallucination detection.
Mahey Qadir

It’s no surprise that hallucinations are a common known failure during agentic AI testing. The agent starts to overpromise, begins to fabricate answers and even claims that it…
Voxli